Speech to Text
Rhasspy's primary function is convert voice commands to JSON events. The first step of this process is converting speech to text (transcription).
Available speech to text systems are:
The following table summarizes language support for the various speech to text systems:
| Language | pocketsphinx | kaldi | deepspeech |
|---|---|---|---|
| ca | ✓ | ||
| cs | ✓ | ||
| de | ✓ | ✓ | ✓ |
| el | ✓ | ||
| en | ✓ | ✓ | ✓ |
| es | ✓ | ✓ | ✓ |
| fr | ✓ | ✓ | ✓ |
| hi | ✓ | ||
| it | ✓ | ✓ | ✓ |
| nl | ✓ | ✓ | |
| pl | ✓ | ✓ | |
| pt | ✓ | ✓ | |
| ru | ✓ | ✓ | |
| sv | ✓ | ||
| vi | ✓ | ||
| zh | ✓ |
Silence Detection
You can adjust how Rhasspy detects the start and stop of voice commands. Add to your profile:
"command": {
"webrtcvad": {
"skip_sec": 0,
"min_sec": 1,
"speech_sec": 0.3,
"silence_sec": 0.5,
"before_sec": 0.5,
"silence_method": "vad_only",
"vad_mode": 1,
"max_energy": "",
"max_current_energy_ratio_threshold": "",
"current_energy_threshold": ""
}
}
}
where:
skip_secis how many seconds of audio should be ignored before recordingmin_secis the minimum number of seconds a voice command should lastspeech_secis the seconds of speech before a command startssilence_secis the seconds a silence after a command before endingbefore_secis how many seconds of audio before a command starts are keptsilence_methoddetermines how Rhasspy detects the end of a voice commandvad_only- only webrtcvad is usedcurrent_only- audio frames whose energy is abovecurrent_energy_thresholdare considered speechratio_only- audio frames whose ratio of max/current energy is belowmax_current_energy_ratio_thresholdare considered speech (seemax_energy)vad_and_current- both VAD and current audio energy are usedvad_and_ratio- both VAD and max/current energy ratio are usedall- VAD, current energy, and max/current energy ratio are all used
vad_modeis the sensitivity of speech detection (3 is the least sensitive)current_energy_threshold- frame with audio energy threshold above this value is considered speechmax_current_energy_ratio_threshold- frame with ratio of max/current energy below this value is considered speechmax_energy- if not set, max energy is computed for every audio frame; otherwise, this fixed value is used
Implemented by rhasspy-silence
ASR Confidence
Each ASR system reports word-level and overall sentence confidences (see asrTokens in asr/textCaptured).
- Pocketsphinx
- Sentence confidence is
exp(p)wherepis the hypothesis probability - Word confidences are
exp(p)wherepis the segment probability
- Sentence confidence is
- Kaldi
- Sentence confidence is the result of MinimumBayesRisk.GetBayesRisk
- Word confidences are the result of MinimumBayesRisk.GetOneBestConfidences
- See online2-cli-nnet3-decode-faster-confidence.cc
- DeepSpeech
- Sentence confidence is
exp(c)wherecis the metadata confidence value - Word confidences are always set to 1
- Sentence confidence is
The rhasspy-dialogue-hermes will use the value of speech_to_text.<SYSTEM>.min_confidence to decide when a voice command should be rejected as not recognized (where <SYSTEM> is pocketsphinx, kaldi, or deepspeech). This is set to 0 by default, allowing all voice commands through.
In the web interface, look for "Minimum Confidence" in the settings for your speech to text system:

MQTT/Hermes
Rhasspy transcribes audio according to the Hermes protocol. The following steps are needed to get a transcription:
- A
hermes/asr/startListeningmessage is sent with a uniquesessionId - One or more
hermes/audioServer/<siteId>/audioFramemessages are sent with WAV audio data - If enough silence is detected, a transcription is attempted
- A
hermes/asr/stopListeningmessage is sent with the samesessionId. If a transcription has been sent, it will be.
Either a hermes/asr/textCaptured or a hermes/error/asr message will be sent in response.
Pocketsphinx
Does speech recognition with CMU's pocketsphinx. This is done completely offline, on your device. If you experience performance problems (usually on a Raspberry Pi), consider running on a home server as well and have your client Rhasspy use a remote HTTP connection.
Add to your profile:
"speech_to_text": {
"system": "pocketsphinx",
"pocketsphinx": {
"acoustic_model": "acoustic_model",
"base_dictionary": "base_dictionary.txt",
"custom_words": "custom_words.txt",
"dictionary": "dictionary.txt",
"language_model": "language_model.txt"
}
}
The dictionary, language_model, and unknown_words files are written during training by the default speech to text training system. The acoustic_model and base_dictionary components for each profile were taken from a set of pre-trained models. Anyone can extend Rhasspy to new languages by training a new acoustic model.
When Rhasspy starts, it creates a pocketsphinx decoder with the following attributes:
hmm-speech_to_text.pocketsphinx.acoustic_model(directory)dict-speech_to_text.pocketsphinx.dictionary(file)lm-speech_to_text.pocketsphinx.language_model(file)
Open Transcription
If you just want to use Rhasspy for general speech to text, you can set speech_to_text.pocketsphinx.open_transcription to true in your profile. This will use the included general language model (much slower) and ignore any custom voice commands you've specified. For English, German, and Dutch, you may want to use Kaldi instead for better results.
Implemented by rhasspy-asr-pocketsphinx-hermes
Kaldi
Does speech recognition with Kaldi. This is done completely offline, on your device. If you experience performance problems (usually on a Raspberry Pi), consider running on a home server as well and have your client Rhasspy use a remote HTTP connection.
{
"speech_to_text": {
"system": "kaldi",
"kaldi": {
"base_dictionary": "base_dictionary.txt",
"compatible": true,
"custom_words": "custom_words.txt",
"dictionary": "dictionary.txt",
"graph": "graph",
"kaldi_dir": "/opt/kaldi",
"language_model": "language_model.txt",
"model_dir": "model",
"unknown_words": "unknown_words.txt",
"language_model_type": "arpa"
}
}
}
Rhasspy currently supports nnet3 and gmm Kaldi acoustic models.
This requires Kaldi to be installed, which is...challenging. The Docker image of Rhasspy contains a pre-built copy of Kaldi, which might work for you outside of Docker. Make sure to set kaldi_dir to wherever you installed Kaldi.
Language Model Type
By default, Rhasspy generates an ARPA language model from your custom voice commands. This model is somewhat flexible, allowing minor deviations from the prescribed templates. For longer voice commands or when you have slots with many possibilities, this language modeling approach can cause recognition problems.
Setting speech_to_text.kaldi.language_model_type to "text_fst" instead of "arpa" will cause Rhasspy to directly convert your custom voice command graph into a Kaldi grammar finite state transducer (G.fst). While less flexible, this approach will only ever produce sentences from your templates.
Open Transcription
If you just want to use Rhasspy for general speech to text, you can set speech_to_text.kaldi.open_transcription to true in your profile. This will use the included general language model (much slower) and ignore any custom voice commands you've specified.
Unknown Words
When you use "text_fst" for Kaldi's language model type, misspoken words outside of your vocabulary are usually forced to fit. Even with confidence measures, it can be difficult to tell the difference between a correctly spoken sentence and random words.
As of version 2.5.11, setting speech_to_text.kaldi.allow_unknown_words to true will enable a new "unknown words" mode for Kaldi (in the web interface, this option is titled "Replace unknown words with <unk>"):
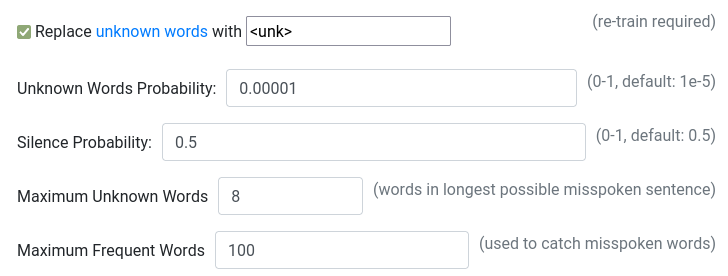
When "unknown words" mode is enabled, training will take longer and produce two grammars:
- An "unknown words" grammar made from a list of frequently-spoken words in your profile's language
- A grammar created from your
sentences.inifile, but with an optional "sentence" made entirely of "unknown words"
Combined, these two grammars allow Kaldi to generate <unk> words if you speak a sentence outside of your sentences.ini file. Frequently-spoken words are used under the assumption that they will contain a good mix of phonemes, and therefore "catch" most misspoken words.
A few profile settings are available to tune the overall process:
speech_to_text.kaldi.unknown_words_probability- Probability of of an unknown sentence being spoken (defaults to 1e-5)
- Decrease if you get too many false positives for unknown sentences
speech_to_text.kaldi.max_frequent_words- Number of frequent words to use during training (default: 100)
- Increasing this number will also increase training time
- Only increase if you can't get the desired behavior by change
unknown_words_probability
speech_to_text.kaldi.unknown_token- Transcription word emitted when an unknown word is encountered
- Defaults to
<unk> - Can be empty!
speech_to_text.kaldi.frequent_words- Path to a text file containing frequently-spoken words, one per line
- A file named
frequent_words.txtis already included in all profiles
After speech recognition, it will be the intent recognizer's job to decide what to do with unknown words in the transcription. By default, the word <unk> is emitted in place of unknown words (this can be changed with speech_to_text.kaldi.unknown_token). fsticuffs, for example, will produce a failed recognition if any <unk> words are present (see intent.fsticuffs.failure_token).
Cancel Word
As of version 2.5.11, a "cancel" word can be given to terminate a (Kaldi) voice command at any time:

Under the hood, this creates an alternative branch for each word in you sentences.ini that accepts the "cancel" word (speech_to_text.kaldi.cancel_word) and emits <unk> (or whatever speech_to_text.kaldi.unknown_token is set to). This will increase training and recognition time.
There are three settings associated with this feature:
speech_to_text.kaldi.cancel_word- Word spoken at any time to terminate voice command
- Should not be one of the words you use in
sentences.ini
speech_to_text.kaldi.cancel_probability- Probability of "cancel" word being spoken instead of the next word in your voice command
- Defaults to 1e-2
- Decrease if the "cancel" word is being recognized too often
speech_to_text.kaldi.unknown_token- Transcription word emitted when an "cancel" word is encountered
- Defaults to
<unk> - Can be empty!
After cancellation, it will be the intent recognizer's job to decide what to do with the transcription. By default, the word <unk> is emitted for the "cancel word", which will cause fsticuffs, to produce a failed recognition (see intent.fsticuffs.failure_token).
Implemented by rhasspy-asr-kaldi-hermes
DeepSpeech
Does speech recognition with Mozilla's DeepSpeech version 0.9. This is done completely offline, on your device. If you experience performance problems (usually on a Raspberry Pi), consider running on a home server as well and have your client Rhasspy use a remote HTTP connection.
{
"speech_to_text": {
"system": "deepspeech",
"deepspeech": {
"alphabet": "deepspeech/model/0.6.1/alphabet.txt",
"acoustic_model": "deepspeech/model/0.6.1/output_graph.pbmm",
"base_language_model": "deepspeech/model/0.6.1/base_lm.binary",
"base_trie": "deepspeech/model/0.6.1/base_trie",
"compatible": true,
"language_model": "deepspeech/lm.binary",
"trie": "deepspeech/trie",
"open_transcription": false
}
}
}
Uses the official deepspeech library, an appropriate native client, and KenLM for building language models. For English, Rhasspy automatically uses Mozilla's TFLite graph on the Raspberry Pi (armv7l).
Open Transcription
If you just want to use Rhasspy for general speech to text, you can set speech_to_text.deepspeech.open_transcription to true in your profile. This will use the included general language model (much slower) and ignore any custom voice commands you've specified. Beware that the required downloads are quite large (at least 1 GB extra).
Implemented by rhasspy-asr-deepspeech-hermes
Remote HTTP Server
Uses a remote HTTP server to transform speech (WAV) to text.
The /api/speech-to-text endpoint from Rhasspy's HTTP API does just this, allowing you to use a remote instance of Rhasspy for speech recognition.
This is typically used in a client/server set up, where Rhasspy does speech/intent recognition on a home server with decent CPU/RAM available.
Add to your profile:
"speech_to_text": {
"system": "remote",
"remote": {
"url": "http://my-server:12101/api/speech-to-text"
}
}
During speech recognition, 16-bit 16 kHz mono WAV data will be POST-ed to the endpoint with the Content-Type set to audio/wav. A application/json response with the {text: "transcribed text"} transcription is expected back.
Implemented by rhasspy-remote-http-hermes
Home Assistant STT Platform
Not supported yet in 2.5!
Use an STT platform on your Home Assistant server. This is the same way Ada sends speech to Home Assistant.
Add to your profile:
"speech_to_text": {
"system": "hass_stt",
"hass_stt": {
"platform": "...",
"sample_rate": 16000,
"bit_size": 16,
"channels": 1,
"language": "en-US"
}
}
The settings from your profile's home_assistant section are automatically used (URL, access token, etc.).
Rhasspy will convert audio to the configured format before streaming it to Home Assistant. In the future, this will be auto-detected from the STT platform API.
Command
Calls a custom external program to do speech recognition. WAV audio data is provided to your program's standard in, and a transcription is expected on standard out.
Add to your profile:
"speech_to_text": {
"system": "command",
"command": {
"program": "/path/to/program",
"arguments": []
}
}
The following environment variables are available to your program:
$RHASSPY_BASE_DIR- path to the directory where Rhasspy is running from$RHASSPY_PROFILE- name of the current profile (e.g., "en")$RHASSPY_PROFILE_DIR- directory of the current profile (whereprofile.jsonis)
See speech2text.sh for an example program.
If you want to also call an external program during training, add to your profile:
"training": {
"system": "auto",
"speech_to_text": {
"command": {
"program": "/path/to/training/program",
"arguments": []
}
}
}
If training.speech_to_text.command.program is set, Rhasspy will call your program with the intent graph generated by rhasspy-nlu provided as JSON on standard input. No response is expected, though a non-zero exit code indicates a training failure.
Implemented by rhasspy-remote-http-hermes
Dummy
Disables speech to text decoding.
Add to your profile:
"speech_to_text": {
"system": "dummy"
}